

Batch Integration
Mantis documentation
This section details the process of a ‘Batch Integration’ with Mantis.
1. Article brand safety classification
When an article is to be analysed there are two approaches to integration with Mantis.
- Mantis synchronous HTTP API endpoint
- Mantis Asynchronous Batch File upload and retrieval
These are explained in more detail below.
Mantis Synchronous HTTP API
Call the Mantis ‘classifyArticle’ api endpoint for the customer Mantis account (to be provided) e.g.
https://<publisher-mantis-url>/classifyArticle
– POST article data in the call to this URL, as a JSON object in the request body including:
- HTML content (just send the article body content itself, not a whole page with headers/footers/links and teasers for other articles/commercial and other embedded components) – or plain text of the article content.
- Public Page URL
- CMS id (publisher specific unique article reference id)
- Author(s)
- Title
- Published/last modified timestamps
– Pass publisher authentication credentials (to be provided) using an HTTP Basic authentication header
The article will be processed and Brand Safety ratings will be generated – and returned from the Mantis API in the response body as JSON data.
In order to analyse multiple articles at once, the endpoint will accept either a single JSON object describing one file, or an array of objects (one for each file to be processed). If an array of article data objects is passed then the response will also be an array of data objects with ratings for each file. However, it is important to note that this HTTP API operates synchronously and will have to process all articles before a response is sent . It is therefore only suitable for very small batches of files. If larger batches of files are required to be processed then the asynchronous batch file processing interface should be used (see below).
Mantis Asynchronous Batch File Processing
The data formats used to process larger batches of articles are very similar to those used with the synchronous HTTP API endpoints – containing arrays of JSON data objects describing the files to be processed and the ratings for each processed article.
However, in order to accommodate larger batches, the article data is uploaded as separate files to the Mantis platform.
The primary integration method for file upload uses the IBM Cloud Object Storage. A customer-specific storage bucket will be provisioned and the files containing the article data should be uploaded to this bucket.
Details of how to integrate with the IBM Cloud Object Storage can be found here:
https://cloud.ibm.com/docs/services/cloud-object-storage/hmac?topic=cloud-object-storage-upload
Once the files are uploaded they will be processed by the Mantis analyser and the results will be stored as new files in the same storage bucket – from which they can be downloaded as required.
2. Article brand safety retrieval
When an article page is built in the publisher CMS backend, the results can be made available on page by either:
– Calling the publisher Mantis API endpoint with a GET request passing one of the following in a query parameter
- Publisher’s CMS article id (recommended)
- Public page URL
– Retrieving the locally stored ratings data, downloaded from the batch or HTTP API endpoints
When calling the Mantis API endpoint, Brand Safety ratings will be retrieved from the Mantis data store and returned in the response body as JSON data. If the requested article has not yet been processed by Mantis, then the JSON response will indicate that the article ratings are not yet available.
For a backend integration, we would suggest adding a static script tag to the page which includes the ratings retrieved from the Mantis api as a global object on the page:
<script>
window.mantis = {ratings object from Mantis};
<script>
Publishers can, of course, customise to their own requirement and directly include the ratings data in any code delivered from their CMS backend.
If defined as in the above example, the ratings data from the global ‘mantis’ object can also be read in any frontend script integrations (e.g in Ad tags, where we recommend passing in a list of ratings values as a ‘mantis’ key/value pair in page level targeting).
3. Request and response JSON data formats
HTTP POST requests
classifyArticle POST requests should send article data in the request body, as a single JSON object, or optionally an array of objects as in the following example:
[{
"html": "<title><h1>FA reveal bans for Port Vale's Mitch Clark and Tom Pope</h1></title><h2> <p>Mitch Clark and Tom Pope were sent off in the closing stages of Port Vale's 3-2 win at Forest Green</p> </h2><p>Port Vale duo Mitch Clark and Tom Pope face three and one game bans respectively.</p> <p>The bans have been confirmed on the FA’s website this morning after both were sent off in last night’s 3-2 win at Forest Green Rovers.</p> ... <p><a data-content-type=\"section-topic\" data-link-tracking=\"InArticle|Link\" href=\"https://www.stokesentinel.co.uk/all-about/port-vale-fc\">For all your latest Port Vale news and analysis, click here</a></p>",
"cmsID": "stokesentinel-3838610",
"url": "www.stokesentinel.co.uk/sport/football/port-vale-pope-clark-bans-3838610",
"author": "Michael Baggaley",
"published": "2020-02-01T11:27:15.000Z",
"lastModified": "2020-02-01T11:27:15.000Z",
"title": "FA reveal bans for Port Vale's Mitch Clark and Tom Pope"
}, {
"cmsID": "mirror-21482732",
"url": "www.mirror.co.uk/news/uk-news/inside-lonely-coronavirus-quarantine-masked-21482732",
"author": "Matthew Dresch",
"published": "2020-02-12T14:43:27.000Z",
"title": "Inside lonely coronavirus quarantine where masked Brits have meals left at the door"
}]
Request object details
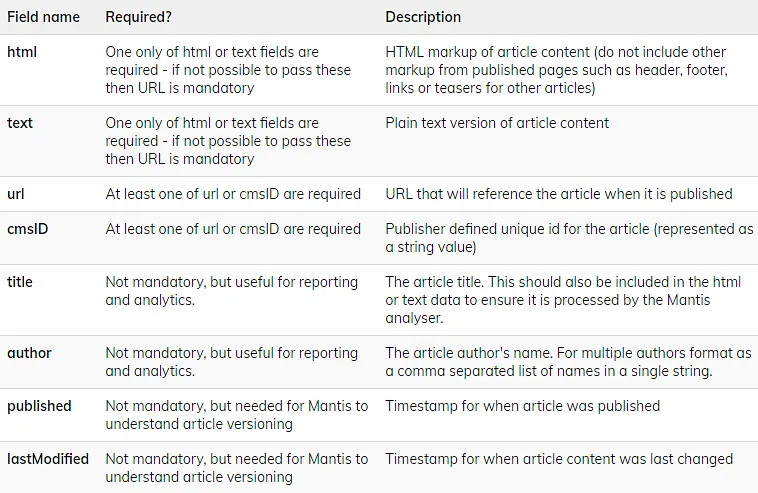
Batch file upload formats
The data format for files uploaded to the batch processor is the same as the request object data format in HTTP endpoint detailed above, but can support much larger numbers of articles included for analysis in a single file.
For customisation, to support other file upload formats please contact us to discuss the requirements.
HTTP GET requests
classifyArticle GET requests should pass the article URL or CMS id as a query parameters in the request, e.g.
https://<publisher-mantis-url>/classifyArticle?cmsID=stokesentinel-3838610
or
https://<publisher-mantis-url>/classifyArticle?url=www.stokesentinel.co.uk/sport/football/port-vale-pope-clark-bans-3838610
Response Data
Both POST and GET requests will return results in the response body as in the following examples:
Success:
{
input: {
html: "...",
cmsID: "mirror-21482732",
url: "www.mirror.co.uk/news/uk-news/inside-lonely-coronavirus-quarantine-masked-21482732",
author: "Matthew Dresch",
published: "2020-02-12T14:43:27.000Z",
title: "Inside lonely coronavirus quarantine where masked Brits have meals left at the door"
},
ratings: [{
customer: "Default",
rating: "RED",
ruleSetVersion: 5
}, {
customer: "Custom Ruleset 1",
rating: "AMBER",
ruleSetVersion: 5
}, {
customer: "Custom Ruleset 1",
rating: "GREEN",
ruleSetVersion: 5
}]
}
Response object details

Other fields may be present with a more detailed breakdown of the rules that resulted in the brand safety rating – if this has been enabled in the Mantis API platform.
If multiple articles are submitted for processing in a single request, then the response will be an array of objects.
Failure:
The response will include an ‘error’ field in the JSON data, with a description of the error that occurred.
{
error: "Article id not found"
}
4. Ratings description
The Watson ML system and Mantis Brand Safety Engine work together to determine the Brand safety rating for an article, using a set of customisable Brand Safety rulesets.
When an article is analysed a variety of semantic data is extracted from the content and is correlated against thresholds defined in the rulesets.
If any individual element is found to exceed the Brand Safety threshold in the ruleset, then this will automatically trigger a “RED” rating (Content is NOT brand safe).
If none of the extracted data matched in the ruleset, then this automatically triggers a “GREEN” rating (Content IS brand safe).
Finally, if any of the extracted data is matched in the ruleset, but at less than the configured Brand Safety threshold, the article is given an “AMBER” rating (potentially brand unsafe). How this would be used depends on publisher and advertiser preferences. Ideally the ruleset would be tuned for a particular purpose, and use of the Amber rating can be used to balance between very conservative brand safety settings and availability of inventory for campaigns (while still ensuring that all unsafe content can be clearly identified).